
◆ GeForce GTX 200并行计算架构
前面说过,GTX 200不再仅是一块娱乐级的显卡,开始注重非游戏的密集型计算任务,这也是GTX 200与以往GPU最大的不同,GTX 200的并行计算架构为NVIDIA倡导的GPU Computing打下了坚实基础。

|
|
上图展示了GTX 280在并行运算模式下的架构,一个硬件级别的线程管理器在最上方,管理着TPC所处理的不同线程。除此以外你还可以轻易发现在在并行运算架构下该图还包括了纹理缓存和显存位宽单元(memory interface unit)。纹理缓存用以和显存相结合,提高缓存的读取效率,加大带宽和加快读写速度。“Atomic”单元能够执行显存的读取-改动-写入操作,该单元能够提供到显存位置的granular access,帮助减少并行运算数据存储量以及数据存储管理。
|
|
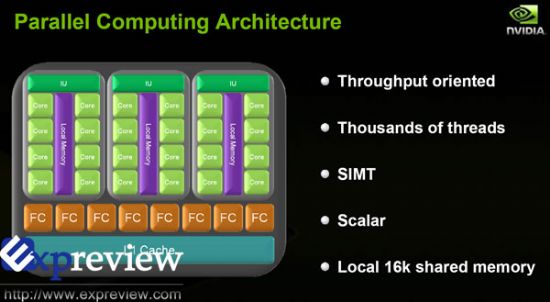
一个TPC(Thread Processing Cluster)在并行计算模式下的结构如上图,可以看见每三个SMs内都有一个逻辑的16k大小的共享缓存,每一个流处理器核心都能够和SM内的其他核心共享信息,省下了从外部缓存系统中读取信息的时间,这种设计大大加快了处理器的运算速度,同时提高了各种算法的效率。

在并行计算模式下,Streaming Processor称之为Thread Processor(线程处理器),仍然是前代的标量设计,即1MAD+2SFU,因此对于GTX 280来说,其浮点运算能力达到了933GFLOPs(3*1296*240=933120),几乎是Intel四核处理器9650的十倍之多,意味着GPU在浮点运算中有得天独厚的优势。












 康佳平板电视
康佳平板电视 创维平板电视
创维平板电视
 LG平板电视
LG平板电视 长虹平板电视
长虹平板电视 WAP手机版
WAP手机版 建议反馈
建议反馈 官方微博
官方微博 微信扫一扫
微信扫一扫