
◆ GTX 200的主要改进
·SIMT架构
NVIDIA的统一渲染以及运算架构使用了两种不同的处理模式,在使用TPC执行指令时该模式被称为MIMD(Multiple instruction multiple data),在使用每一个SM执行指令时,模式被称为SIMT(single instruction, multiple thread)。
SIMT改进了纯SIMD(single instruction, multiple data)设计,能够同时保证性能以及可编程特性。在拥有可扩充性的同时,SIMT并没有一个固定的矢量宽度(vector width),这使得在SIMT处理模式下,运算速度可以全速展开,完全和矢量宽度脱离关系。
相反,如果输入信息较MIMD或SIMD宽度少的话,SIMD模式会开始低负载运作,SIMT保证所有流处理器能够在任何使用都能够被充分利用。在一个编程者的角度来看,SIMT同样允许线程使用自己的路径。由于分支机构(branching)是由硬件来控制的,所以并不需要在矢量宽度(vector width)内手动管理分支。
·同时支持大量线程
GTX 200系列显卡的GPU能够同时支持超过三万个线程(thread),基于硬件的线程管理保证了所有流处理器核心能够100%全部利用。核心架构的设计避免CPU内经常出现的延时问题:如果某个线程正在等待读取缓存信息,那么GPU能够实现一个完全即时没有损耗的转换,将另一个等待处理的线程交由空闲部分继续处理。
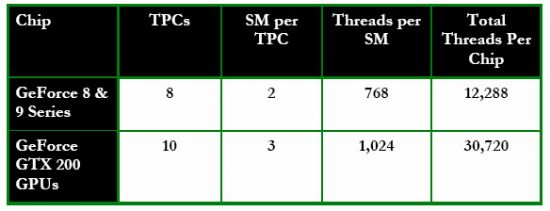
SIMT多线程指令单元处在SM内部,能够管理安排以及处理一组32个平行的线程,被称为"warps"。前一代的GeForce 8或者GeForce 9 GPU每SM只能同时处理24个warps,而GTX 200系列显卡的GPU能够达到32warps/SM的效率。我们可以看到,凭借SM以及TPC数量的增多,可同时处理的线程数量也由GeForce 8和9系列的12888上升至30720个(1024*3*10=30720)。
·加大的寄存器组
和GeForce 8或9系产品相比,在GTX200系列显卡中本地寄存器组的大小增加了一倍,在以往,寄存器组往往会因为过小导致信息必须转存至显存中,增大的寄存器组能够允许显卡更快速有效地处理大且复杂的shader。虽然寄存器组容量加大了,不过在核心die内这些额外的寄存器只占用了不多的些许面积。
现在的游戏越来越多地使用复杂的shader,需要更加大的寄存器组空间。
·改进的Dual Issue
在SM内部的特殊功能单元(Special Function Unit,SFU)负责超越数的运算,属性插值(从一个原始的顶点属性中解释像素属性,interpreting pixel attributes from a primitive vertex attributes),以及处理浮点MUL指令。GT200内每一个独立的流处理核心都以几乎全速的速度,用Dual issue的方法来运算:使用核心内部的MAD单元处理MADs(multiply add operations)以及MULs(3flops/SP),另外在同一时间也使用SFU单元来进行MUL运算。改进和直接的测试表明这种结构能够带来93%~94%的效率。
在GPU内部的所有特殊功能单元阵列能够为显卡带来几乎1Tflops的single -precision, IEEE 754浮点运算能力。
·支持双精度浮点运算
在GTX 200核心架构内部有一个非常重要的新特点:支持double precision、64bit双精度浮点运算。这对高端的科学工程以及金融运算更加有利,能够为其带来非常高精确度的结果,每一个SM内都有一个double-precision 64bit的浮点运算单元,整个芯片内总共有30个。
这些double precision单元能进行融合的MAD演算,完全兼容与IEEE 754R浮点运算规格。所有TPC内部的double precision性能几乎等同与一个八核的XeonCPU,接近90Gflops。
·改进的纹理性能
8800GTX核心内部拥有8个TPC,允许进行每频率内64像素的纹理过滤,每频率32像素寻址,每频率32像素的两倍反锯齿双线性过滤(8bit整数)或者32-双线性过滤像素(8bit整数或者16bit浮点),而GTX 200改进的纹理性能平衡了寻址能力和过滤能力。
·提高Shader to texture比例
由于游戏和其他图形程序的需要,系统正在使用越来越多的复杂化shader,为了重新平衡显卡的运算能力,GTX 200系列GPU的设计重新调整了Shader to texture的比例,通过在TPC内部增加1个SM让Shader to texture的比例上升了50%,这让GTX 200系列显卡在处理目前以及将来的游戏时能够更加有效率。
·ROP改进
GeForce 8系列的ROP系统支持multisampled,supersampled,透明适应以及Sampling抗锯齿等功能,对于GTX 200同样支持这些特性,ROP单元数量由6个增加到8个之外,总的ROPs数达到32个,相对于G80每时钟周期24像素的输出和12像素的混合速度,GTX 200均提升至每时钟周期32像素,更加有利于高分辨率以及AA环境中速度的提升。
·1GB的Framebuffer
现在的3D游戏采用了大量的纹理来提高画面的真实度,例如用普通的map提高表面真实度,用立方map来增强反射效果,用高分辨率的perspective shadow map来模拟soft shadow。这些map使得渲染每一帧画面都需要大量的显存,而不像传统的游戏,有base texture就可以了。另外,Deferred rendering引擎在multiple render时,需要有一个预先渲染图片特性的过程,这意味着又需要额外的显存,还有就是很耗显存的反锯齿技术,这些技术使得内存和带宽的需求都大大高于以前。
Geforce GTX 280和GTX 260分别支持1024MB和896MB的Framebuffer,是上一代显卡的两倍。1GB显存将使高分辨率的反锯齿能力得到提升。
·几何shading和stream out
比起上一代显卡,GTX 200将内部缓存输出结构提高了6倍,使几何渲染和stream out的速度大大提升。
·512bit显存接口
GTX 200的最大显存带宽从原来的384bit提高到了512bit,拥有8个64-bit-wide FrameBuffer单元,为了使texture单元在被有效利用的同时,又不会出现不足,FreamBuffer带宽需要反复调整达到最佳,NVIDIA的工程师测试了许多应用程序,最终达到了这个目的。
GTX 200 GPu的framebuffer总效率得到了提高,为了支持更高速度的显存,重新设计了framebuffer重要的path,使得显卡最高能支持到1.1GHz的DDR3显存,内存的存取模式和缓存算法也都得到了改良。另外硬件压缩加大了数据传输率,而实际上是增加了framebuffer带宽,也提升了显卡在高分辨率下的性能。












 康佳平板电视
康佳平板电视 创维平板电视
创维平板电视
 LG平板电视
LG平板电视 长虹平板电视
长虹平板电视 WAP手机版
WAP手机版 建议反馈
建议反馈 官方微博
官方微博 微信扫一扫
微信扫一扫