
前言

全新的GTX 200千呼万唤始出来
◆
自从2006年11月NVIDIA革命性统一架构(Unified Shader)的G80诞生以来,基于G8x核心的显卡有8800GTX、8800GTS、8600 GTS、8600 GT、8500 GT、8400 GS、8800 Ultra,以G80为基础的基于G9x核心的显卡有8800GT、8800GTS 512、8800GS、9600GT、9800GX2,在18个月时间内,NVIDIA依靠成熟的G80架构,衍生出数代GPU产品,显然这些产品都是换汤不换药,简单的改良设计加上规格上的增减,让NVIDIA赚得盆满钵满。
NVIDIA的老大创建的所谓“黄氏定律”,声称将每六个月将产品升级一次,性能翻番,然而NVIDIA在过去的一年内略显沉寂,我们一直期待有突破性的产品面世,直到今天,2008年6月16日,全新的NVIDIA GeForce GTX 200系列显卡才在千呼万唤中步入历史舞台。

|
|
GeForce GTX 200系列显卡的GPU不仅使用了第二代的统一渲染架构,更加入了相比前代性能大有提升的并行计算架构。GTX 280的开发遵循着两个原则即"Beyond Gaming"以及"Gaming Beyond"。
Beyond Gaming指的是GPU的架构目前已经进化到不仅仅只用来运算3D游戏的画面。GPU面临的工作不但有游戏,还包括了针对普通用户和专家的非游戏密集运算型程序。
Gaming Beyond指GTX 200系列显卡能够发挥出惊人的画面效果,带来完全真实的画面体验以及细致的人物纹理,同时带来准确的物理特效。

|
|
GTX 200新架构设计目标:
- 核心性能是8800GTX的两倍;
- 为未来游戏使用的大量复杂shader以及显存改变核心架构设计,让其性能更加平衡;
- 改进架构内每瓦效能以及每平方毫米效能;
- 为DirectX10的特性而改变Geometry Shading以及Stream Out
- 提高特别为CUDA以及GPU物理运算(PhysX)而加强的运算性能。
- 改进电源管理能力,包括待机状态下显著减少的能源消耗。
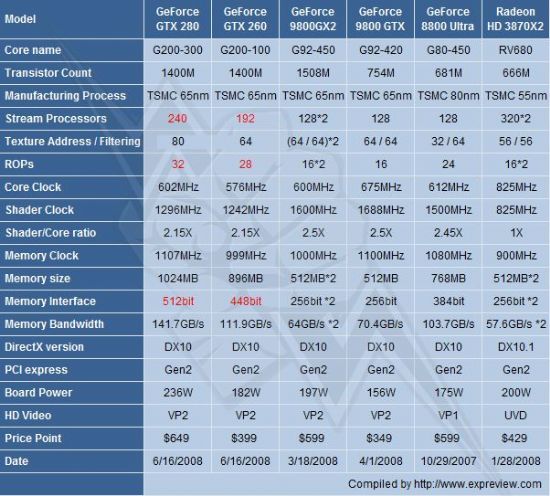
NVIDIA GeForce GTX 200系列显卡有两种型号,即全规格的GTX 280和稍低规格的GTX 260。
GeForce GTX 200图形处理架构
◆
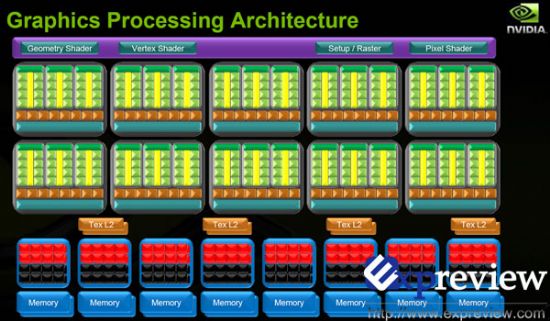
GTX 200是首款使用NVIDIA第二代统一架构渲染及运算引擎的显卡。对比GeForce 8或者9系显卡,新架构能够带来约1.5倍的性能增长。
|
|
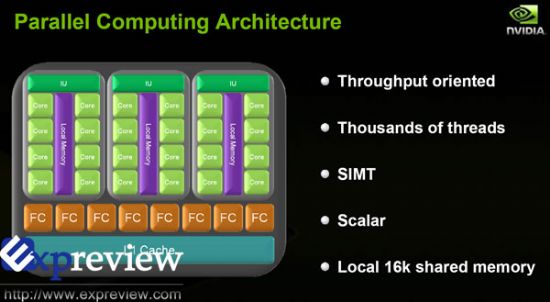
想必大家都记得GeForce 8系列以及GeFeforce 9系列的核心是基于一个可扩展处理器阵列(Scalable Processor Array,SPA)结构,GTX 200系列所用的是一个重新设计加强以及延展的SPA结构。
SPA结构里面包含了一些TPC单元,TPC的全称根据用途的不同而有所不同。在图形处理模式时它被称为贴图处理群(Texture Processing Cluster),而在并行计算模式时它被称为线程处理群(Thread Processing Cluster)。每一个TPC包含了一定数量的流处理单元(Streaming multiprocessors,SMs),而每一个流处理单元内部又包含了8个流处理器核心(Stream Processors,SPs,或者thread Processors)。另外,每一个SM内部也包含了一定数量的纹理过滤处理器(Texture Filtering Processor),除了在3D图形模式上有着很大的作用之外,在运算模式下也非常有用处,如大型图像的放大缩小等等。
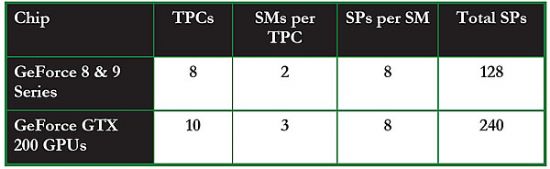
第二代统一渲染架构和G80以及G92所使用的第一代统一渲染架构相比,在两方面有着巨大的进步。首先,每一个TPC内的SM数目从第一代的两个增加至三个;第二是每一个GPU内的TPC从8个增加至10个(GTX 260为8个),TPC和SM数量上的增加直接导致了SP的数目增加至240个(GTX 260只有192个)。
|
|
GPU的处理核心SP基于传统的处理器核心设计,能够进行整数,浮点计算,逻辑运算等操作,从硬体设计上看就是一种完全为多线程设计的处理核心,拥有复数的管线平台设计,完全胜任每线程处理单指令的工作。
GPU内的线程分成多种,包括像素、几何以及运算三种不同的类型,在三维图像处理模式下,大量的线程同时处理一个shader program以达到最大化的效率,所以GTX 200 GPU的核心内很大一部分面积都作为计算之用,和CPU上大部分面积都被缓存所占据有所不同,大约估计在CPU上有20%的晶体管是用作运算之用的,而(GTX 200)GPU上有80%的晶体管用作运算。GPU处理的首要目标是运算以及数据吞吐量,而CPU内部晶体管的首要目的是降低处理的延时以及保持管线繁忙,这也决定了GPU在密集型计算比起CPU来更有优势。
从上面的GeForce GTX 280的图形处理架构图可以看到10个TPCs,每个TPCs包含了三个SMs,每个SMs又包含了8个流处理器核心,这样流处理器核心总量达到了240个。
GTX 200的主要改进
◆
·SIMT架构
NVIDIA的统一渲染以及运算架构使用了两种不同的处理模式,在使用TPC执行指令时该模式被称为MIMD(Multiple instruction multiple data),在使用每一个SM执行指令时,模式被称为SIMT(single instruction, multiple thread)。
SIMT改进了纯SIMD(single instruction, multiple data)设计,能够同时保证性能以及可编程特性。在拥有可扩充性的同时,SIMT并没有一个固定的矢量宽度(vector width),这使得在SIMT处理模式下,运算速度可以全速展开,完全和矢量宽度脱离关系。
相反,如果输入信息较MIMD或SIMD宽度少的话,SIMD模式会开始低负载运作,SIMT保证所有流处理器能够在任何使用都能够被充分利用。在一个编程者的角度来看,SIMT同样允许线程使用自己的路径。由于分支机构(branching)是由硬件来控制的,所以并不需要在矢量宽度(vector width)内手动管理分支。
·同时支持大量线程
GTX 200系列显卡的GPU能够同时支持超过三万个线程(thread),基于硬件的线程管理保证了所有流处理器核心能够100%全部利用。核心架构的设计避免CPU内经常出现的延时问题:如果某个线程正在等待读取缓存信息,那么GPU能够实现一个完全即时没有损耗的转换,将另一个等待处理的线程交由空闲部分继续处理。
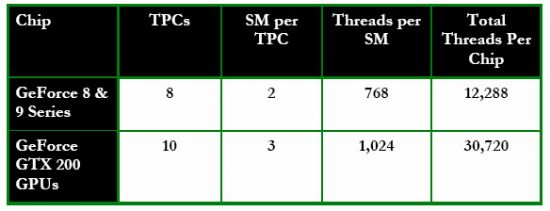
SIMT多线程指令单元处在SM内部,能够管理安排以及处理一组32个平行的线程,被称为"warps"。前一代的GeForce 8或者GeForce 9 GPU每SM只能同时处理24个warps,而GTX 200系列显卡的GPU能够达到32warps/SM的效率。我们可以看到,凭借SM以及TPC数量的增多,可同时处理的线程数量也由GeForce 8和9系列的12888上升至30720个(1024*3*10=30720)。
·加大的寄存器组
和GeForce 8或9系产品相比,在GTX200系列显卡中本地寄存器组的大小增加了一倍,在以往,寄存器组往往会因为过小导致信息必须转存至显存中,增大的寄存器组能够允许显卡更快速有效地处理大且复杂的shader。虽然寄存器组容量加大了,不过在核心die内这些额外的寄存器只占用了不多的些许面积。
现在的游戏越来越多地使用复杂的shader,需要更加大的寄存器组空间。
·改进的Dual Issue
在SM内部的特殊功能单元(Special Function Unit,SFU)负责超越数的运算,属性插值(从一个原始的顶点属性中解释像素属性,interpreting pixel attributes from a primitive vertex attributes),以及处理浮点MUL指令。GT200内每一个独立的流处理核心都以几乎全速的速度,用Dual issue的方法来运算:使用核心内部的MAD单元处理MADs(multiply add operations)以及MULs(3flops/SP),另外在同一时间也使用SFU单元来进行MUL运算。改进和直接的测试表明这种结构能够带来93%~94%的效率。
在GPU内部的所有特殊功能单元阵列能够为显卡带来几乎1Tflops的single -precision, IEEE 754浮点运算能力。
·支持双精度浮点运算
在GTX 200核心架构内部有一个非常重要的新特点:支持double precision、64bit双精度浮点运算。这对高端的科学工程以及金融运算更加有利,能够为其带来非常高精确度的结果,每一个SM内都有一个double-precision 64bit的浮点运算单元,整个芯片内总共有30个。
这些double precision单元能进行融合的MAD演算,完全兼容与IEEE 754R浮点运算规格。所有TPC内部的double precision性能几乎等同与一个八核的XeonCPU,接近90Gflops。
·改进的纹理性能
8800GTX核心内部拥有8个TPC,允许进行每频率内64像素的纹理过滤,每频率32像素寻址,每频率32像素的两倍反锯齿双线性过滤(8bit整数)或者32-双线性过滤像素(8bit整数或者16bit浮点),而GTX 200改进的纹理性能平衡了寻址能力和过滤能力。
·提高Shader to texture比例
由于游戏和其他图形程序的需要,系统正在使用越来越多的复杂化shader,为了重新平衡显卡的运算能力,GTX 200系列GPU的设计重新调整了Shader to texture的比例,通过在TPC内部增加1个SM让Shader to texture的比例上升了50%,这让GTX 200系列显卡在处理目前以及将来的游戏时能够更加有效率。
·ROP改进
GeForce 8系列的ROP系统支持multisampled,supersampled,透明适应以及Sampling抗锯齿等功能,对于GTX 200同样支持这些特性,ROP单元数量由6个增加到8个之外,总的ROPs数达到32个,相对于G80每时钟周期24像素的输出和12像素的混合速度,GTX 200均提升至每时钟周期32像素,更加有利于高分辨率以及AA环境中速度的提升。
·1GB的Framebuffer
现在的3D游戏采用了大量的纹理来提高画面的真实度,例如用普通的map提高表面真实度,用立方map来增强反射效果,用高分辨率的perspective shadow map来模拟soft shadow。这些map使得渲染每一帧画面都需要大量的显存,而不像传统的游戏,有base texture就可以了。另外,Deferred rendering引擎在multiple render时,需要有一个预先渲染图片特性的过程,这意味着又需要额外的显存,还有就是很耗显存的反锯齿技术,这些技术使得内存和带宽的需求都大大高于以前。
Geforce GTX 280和GTX 260分别支持1024MB和896MB的Framebuffer,是上一代显卡的两倍。1GB显存将使高分辨率的反锯齿能力得到提升。
·几何shading和stream out
比起上一代显卡,GTX 200将内部缓存输出结构提高了6倍,使几何渲染和stream out的速度大大提升。
·512bit显存接口
GTX 200的最大显存带宽从原来的384bit提高到了512bit,拥有8个64-bit-wide FrameBuffer单元,为了使texture单元在被有效利用的同时,又不会出现不足,FreamBuffer带宽需要反复调整达到最佳,NVIDIA的工程师测试了许多应用程序,最终达到了这个目的。
GTX 200 GPu的framebuffer总效率得到了提高,为了支持更高速度的显存,重新设计了framebuffer重要的path,使得显卡最高能支持到1.1GHz的DDR3显存,内存的存取模式和缓存算法也都得到了改良。另外硬件压缩加大了数据传输率,而实际上是增加了framebuffer带宽,也提升了显卡在高分辨率下的性能。
GeForce GTX 200并行计算架构
◆
前面说过,GTX 200不再仅是一块娱乐级的显卡,开始注重非游戏的密集型计算任务,这也是GTX 200与以往GPU最大的不同,GTX 200的并行计算架构为NVIDIA倡导的GPU Computing打下了坚实基础。

|
|
上图展示了GTX 280在并行运算模式下的架构,一个硬件级别的线程管理器在最上方,管理着TPC所处理的不同线程。除此以外你还可以轻易发现在在并行运算架构下该图还包括了纹理缓存和显存位宽单元(memory interface unit)。纹理缓存用以和显存相结合,提高缓存的读取效率,加大带宽和加快读写速度。“Atomic”单元能够执行显存的读取-改动-写入操作,该单元能够提供到显存位置的granular access,帮助减少并行运算数据存储量以及数据存储管理。
|
|
一个TPC(Thread Processing Cluster)在并行计算模式下的结构如上图,可以看见每三个SMs内都有一个逻辑的16k大小的共享缓存,每一个流处理器核心都能够和SM内的其他核心共享信息,省下了从外部缓存系统中读取信息的时间,这种设计大大加快了处理器的运算速度,同时提高了各种算法的效率。

在并行计算模式下,Streaming Processor称之为Thread Processor(线程处理器),仍然是前代的标量设计,即1MAD+2SFU,因此对于GTX 280来说,其浮点运算能力达到了933GFLOPs(3*1296*240=933120),几乎是Intel四核处理器9650的十倍之多,意味着GPU在浮点运算中有得天独厚的优势。
让NVIDIA野心勃勃的CUDA
◆

|
|
·GPU+CPU异构运算概述
异构运算(heterogeneous computing)的想法是这样的,通过使用计算机上的主要处理器,如CPU以及GPU来让程序得到更高的运算性能。一般来说,CPU由于在分支处理以及随机内存读取方面有优势,在处理串联工作方面是好手。在另一方面,GPU由于其特殊的核心设计,在处理大量有浮点运算的并行运算时候有着天然的优势。完全使用计算机性能实际上就是使用CPU来做串联工作,而GPU负责并行运算,简单来讲,异构运算就是“使用合适的工具做合适的事情”。
那么什么程序是以串联工作为主而什么程序又是以并行的运算为主呢?其实只有很少很少的程序使用纯粹的串联或者并行的,大部分程序同时需要两种运算形式。编译器、文字处理软件、浏览器、e-mail客户端等都是典型的串联运算形式的程序。而视频播放,视频压制,图片处理,科学运算,物理模拟以及3D图形处理(Raytracing及光栅化)这类型的应用就是典型的并行处理程序。
CUDA是业界的首款并行运算语言,而且其非常普及化,目前有高达7千万的PC用户可以支持该语言,以下三大特点让GTX 280能够完全胜任并行运算:
·GPU运算架构:GTX280的核心是为并行运算所设计的,包含了各种有利于并行运算的特性,如共享缓存设计,Atomic操作以及双精度浮点计算的支持。
·大量核心设计:具有240个运行在1.3GHz的微型核心,GTX280可以说是PC上进行浮点运算的利器。
·大型带宽设计:由于数据的吞吐量大,图形运算程序的效率被CPU上的带宽瓶颈给卡住了,由于GTX280上有8个处于核心内部的显存控制器,GTX 280的显存带宽能够达到142GB/s,大量提高了基于显卡的高清视频压缩、物理模拟以及图像处理程序的效率。
·CUDA是什么?

|
|
CUDA(Compute Unified Device Architecture)是一个新的基础架构,这个架构可以使用GPU来解决商业、工业以及科学方面的复杂计算问题。它是一个完整的GPGPU解决方案,提供了硬件的直接访问接口,而不必像传统方式一样必须依赖图形API接口来实现GPU的访问。在架构上采用了一种全新的计算体系结构来使用GPU提供的硬件资源,从而给大规模的数据计算应用提供了一种比CPU更加强大的计算能力。CUDA采用C语言作为编程语言提供大量的高性能计算指令开发能力,使开发者能够在GPU的强大计算能力的基础上建立起一种效率更高的密集数据计算解决方案。
GPGPU使用图形的API如DirectX或者OpenGL来进行运算,这将需要编程人员拥有大量的图形API以及硬件相关技术。而且,编程架构也收到了随机读取写入以及线程配合的限制。编写并行运算的程序很复杂,因为它涉及到使用大量CPU作为同一个簇共同工作的问题。有的桌面程序由于比较难把单一线程的工作量分配给不同线程工作,需要减慢速度才能和多核CPU配合上,这是由于CPU本来就是一个串行的处理器,大量的CPU需要一个非常复杂的软件与其相配合工作。
CUDA去除了这种需要手动管理平行处理的障碍,使用CUDA为基础编写的程序实际上仍然为一个串行的程序。

·核心架构:GPU VS CPU
- 设计目的:CPU核心设计是越快越好地处理处理线性指令。而GPU的核心设计为越快越好地同时处理多个流指令。
- 晶体管:CPU内使用的晶体管大部分被用来作成指令缓存,等待分配中心,硬件分支预测甚至是大型的核心内缓存。这些特性让其在处理单线程任务时获得高速的性能。GPU内大量的晶体管都被用作处理器阵列,多重线程处理部分,共享型缓存以及数个显存管理器。这些特性并不能加速某个特定线程的处理速度,而是为了千百个线程同时运作,优化线程间通讯,以及保持高速显存带宽而设计的。
- 缓存:CPU使用缓存来减少与内存之间的延时问题。GPU使用缓存(或者软件控制的共享缓存)来加大带宽
- 延时管理:CPU使用大缓存和分支预测部分来处理CPU和其他部分之间的延时。这使用了大量的核心空间,同样也导致了能源消耗量大的问题。GPU利用同时处理大量线程的优势来解决延时问题。如果某个线程正在等待从显存返回的信息,GPU能够将其立刻转向处理其他信息,中间不消耗任何时间差。
- 多线程处理:CPU的每一个核心支持单线程或者双线程。而支持CUDA的GPU内每一个SM(Streaming multiprocessor)都支持多达1024个线程。所以在切换线程的时候GPU是无需浪费额外的运算时间。
- SIMD VS SIMT:CPU使用SIMD(single instruction, multiple data)单元来进行向量处理。而GPU使用SIMT(single instruction multiple thread)来进行可拓展的线程处理,SIMT并不需要编程者来把信息转换成向量处理所需的形式而且它也允许线程的任意分支。
- 显存控制器:Intel CPU 目前并没有将内存控制器整合到核心内,而支持CUDA的GPU整合了8个核心内的显存控制器,如此一来和CPU相比GPU就拥有了多达10倍的内存/显存带宽。

|
|
NVIDIA正是想凭借GTX 200强大的计算能力以及CUDA这个架构,将计算机转变成一个以GPU为计算中心的平台。
GTX 200融入PhysX技术
◆
现在的PhysX物理加速技术广泛应用于超过150款的游戏中,并在各个领域有超过1万名开发者在使用,可支持各种游戏平台。

|
|
今年2月NVIDIA收购了物理加速处理器厂商Ageia,将这一颇有前途的技术收归囊中,显然PhysX物理加速技术自然会逐渐融入到NVIDIA的产品中,NVIDIA在其后称他们正在努力将物理引擎移植到CUDA架构中。全新的GTX 200系列成为NVIDIA高调宣传支持PhysX技术的显卡。
当PhysX结合惊人的GPU并行计算能力,可以提供一个指数倍增的物理处理效能,同时将游戏带入另一个全新的境界,提供各种丰富具有临场感的物理物效游戏场境。

|
|
不过目前的驱动还不支持PhysX,NVIDIA承诺在近一两周内会推出新的驱动以支持PhysX技术,到时游戏玩家就能通过NVIDIA显卡来进行物理加速,而需要调用CPU资源的Havok物理加速引擎将会面临NVIDIA PhysX的挑战。

|
|
GTX 200具有先进的动态电源管理
◆
自G80架构出现之后,NVIDIA放弃了原先GPU中2D、3D频率的区分,无论什么情况下,GPU的频率都是恒定不变的,这种状况一直延续到GeForce GTX 200诞生之前(之前我们评测过的GeForce 9500GT也具有2D/3D频率之分,但9500GT是还未发布的产品)。
而NVIDIA的对手AMD在ATI Radeon HD 3800系列时开始引入Powerplay节能技术,这种技术有助于在GPU空闲或少量使用的状态下减少电量消耗,从而达到降噪节能的目的,也成为AMD显卡的一大卖点,放弃了2D/3D频率之分的NVIDIA显卡显然在这一点上有些吃亏。
到了GTX 200系列,NVIDIA重新引入了电源管理机制,GTX 200 GPU内置了比以往的GPU更动态、更灵活的电源管理,包括4种新的供电模式:
·待机/2D供电模式(约25w)
·蓝光高清回放模式(约35W)
·全3D模式(根据特定情况--最差情况下TDP236W)
·HybridPower模式(实际为0W)
使用支持Hybrid Power的nForce主板,譬如基于780a芯片组的主板,GTX200在系统处理非密集型图形计算或者视频输出的时候可以完全关闭,将处理工作交给主板内置CPU, 在需要进行3D密集型计算功能时,NVIDIA的显卡驱动可以无缝转换到特定的独立显卡模式。
|
|
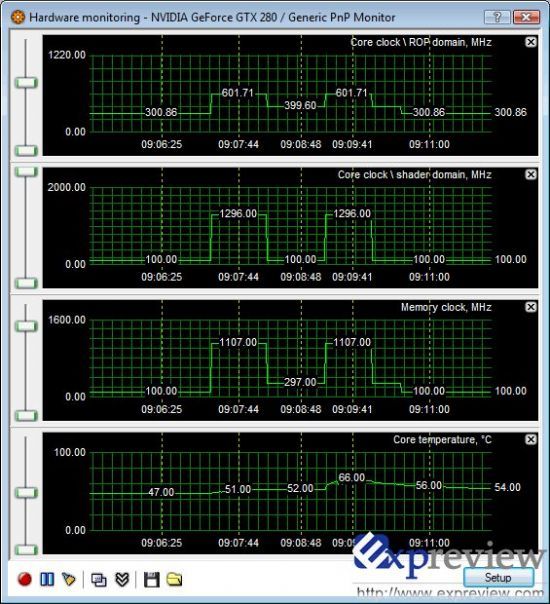
每一张GTX200GPU都内置了监控器,能够即时监控到GPU内部的运行数据,之后给系统驱动发出不同的信号,GPU驱动则根据这些信号,动态地将显卡调整至正确的运行模式(譬如,调整至特定的运行时钟和电压水平),将显卡的耗电量降至最低--而这些步骤用户都无须进行操作,完全自动。
不仅如此,GPU还内含时钟控制电路,能有效地“关闭”特定时间段内(以每千分之一秒计算)未被使用的GPU内部电路区域,加强在非全速运行时减低GPU耗电量的功能。所有这些特色功能能让GTX200显卡实现峰值时的十分之一功耗(GTX280上约为25w),你所有的应用都能被包含在这个省电功能范围内(譬如游戏,视频回放,浏览网页等等) 其他很多部分的GTX200管线都被重新设计以求更强的性能和减少多种数据处理的瓶颈。
对于GTX 280而言,其正常的核心/shader/显存频率应该为602/1296/1107MHz,在待机/2D模式(进行文档处理、浏览网页等)下,其频率会下降到一个相当低的水平,为300/100/100MHz,有轻松的显示负荷时,如播放高清视频,则频率会达到300/100/297MHz,只在在显卡处于较高负荷时,才会在全频率下运行,这样的一种动态电源管理,大大地节省能源消耗。
GeForce GTX 280实物欣赏
◆

 Galaxy的GeForce GTX 280,频率与公版一致 Galaxy的GeForce GTX 280,频率与公版一致 |

| Zotac的GeForce GTX 280 AMP,频率为700/1400/1150MHz(核心/Shader/显存),属于超频版 |


GTX 280与其它三块顶级显卡体积相当,整卡长度同样是26.6cm,均是双卡槽设计,不过风扇的进风口却增大了,从9800 GTX的60mm直径增大到了70mm直径。










GeForce GTX 280内部细节特写
◆











GTX 280的供电模块与以往nVIDIA的高端显卡大不相同,看不到以往那种大量电容矗立的情形,而采用了大量的陶瓷贴片电容,综合性能更好。






NVIO芯片最早出现于G80系列显卡,虽然NVIO功能强大,但实际上G80采用90nm制造工艺,核心的晶体管数已经太多,只好将部分2D功能移出GPU。后来的G92由于采用65nm技术,NVIO芯片被整合到GPU核心。现在GTX 200核心晶体管数达到了14亿,NVIO芯片又只好在外“露宿”了。NVIO芯片真正支持10bit每通道的色彩输出能力,使显卡实现TMDS和双400MHz RAMDAC、双Dual-Link XHD DVI输出功能。

GeForce GTX 280散热器剖析
◆

整卡功耗达到236W的GTX 280对散热器是一个严峻的考验,不过初看起来,这个散热器和9800GTX所用的并没什么大不同,散热面积也只有2000cm^2左右,不过仔细端详之后,你会发现GTX 280散热器上的热管达到了8根之多,这些热管分别将热量从铜底座导向散热鳍片与外壳。








GeForce GTX 260实物欣赏
◆
GTX 260相当于缩水版的GTX 280,TPC只有7个,SP总数为192个,显存位宽为448bit,显存容量只有896MB,核心/显存频率为576/999MHz。

在产品外形上,GTX 260与GTX 280基本一致,只有一些细小的差别,如电源接口GTX 260只需要2个6-pin的PCIE电源接口就可以了,并没有工作状态指示灯。









GTX 260的显存同样是hynix H5RS5223CFR系列,不同的是,GTX 260显存的系列号为N0C,Hynix规定其额定频率只有1000MHz,而NVIDIA规定GTX 260显存工作频率正是1000MHz;另一方面,GTX 280显存的系列号为N2C,额定工作频率为1200MHz,这意味着GTX 260的超频空间将不如GTX 280大。
此外,GTX 260共14颗GDDR3芯片,显存容量为64MBx14=896MB,少于GTX 280的1GB。


GeForce GTX 280高清回放测试
◆
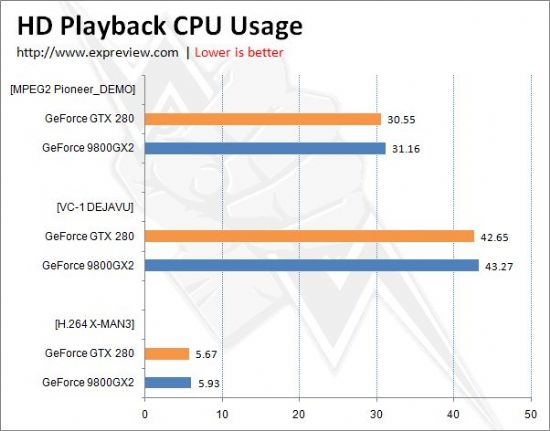
GTX 280在高清回放上并没有作什么特别改进,还是延用了G9X系列的VP2引擎。我们对GTX 280的高清回放性能作了简单测试,为了更好体现它的硬件解码能力,选用了低端的Intel Celeron 460处理器(2.4GHz,12*200MHz),这样可以较合理地测试显卡播放高清视频的能力。
测试片源选用了Remux格式的3部高清视频,分别是采用VC-1视频编码的DEJAVU(时空线索)、H264/AVC编码的X-MAN3(X战警3)、MPEG-2编码的Pioneer_DEMO2006(先锋演示),三大编码齐全。
 GTX 280高清回放测试 GTX 280高清回放测试 |
从CPU占用率可以看出,NVIDIA GeForce GTX 280与NVIDIA其它G9x芯片处于同一水准,具备完整的H.264硬件加速功能,对VC-1编码的视频解码还稍有欠缺,对MPEG2编码,因为其编码相对较简单,目前NVIDIA和AMD都是使用了选择性硬解码,因此CPU占用率也比较高。
实际应用中,与GTX 280这样高端显卡搭配的应该是高端的CPU,因此CPU占用率并没有我们测试的数据这么夸张,比如用QX9650 CPU时,播放VC-1编码视频时,CPU占用率一般只在5%左右,这也是NVIDA一直不在高端显卡中加入全VC-1硬解码的VP3引擎的原因,在高端平台中,VP2足够了。
GeForce GTX 280功耗测试
◆
从前面我们知道,GTX200系列GPU内置了比以往的GPU更动态更灵活的电力控制机制,按NVIDIA官方的资料来说,在待机时整卡功耗只有25W,全3D模式下最多236W,而236W是NVIDIA显卡有史以来最高的功耗(整卡功耗,不单指GPU),看来14亿个晶体管和1GB的显存并非只是用来看的,发热量随之“茁壮成长”,按着NVIDIA提供的数据,搭建GTX 280平台至少需要550W的电源,如果组成SLI系统,则电源要求达到750W。
来看看在实际应用中,GTX 280新的电力管理有什么作用,高负荷下功耗又会达到多少。
测试时所有显卡均为零售产品、默认频率以及使用原装散热器。我们利用Brenenstuhl功耗测试仪记录了实际功耗值,请注意这个成绩指的是整机功耗,而不是独立的显卡功耗,由于平台一致,所以数据是具有参考价值的。
成绩分两种模式获得,一个是在操作系统内待机15分钟,另外一个是使用ATITOOL进行Show 3D View,让显卡在高负荷下运行,记录它们稳定时的功率。
测试平台:
Intel Core 2 Quad QX9650(400MHzX10)
Asustek MAXIMUS EXTREME
ADATA DDR3-1066 1GBx2
Seagate ES.2 500G
Evercool 大黄蜂 CPU Cooler
Silverstone DA750 PSU
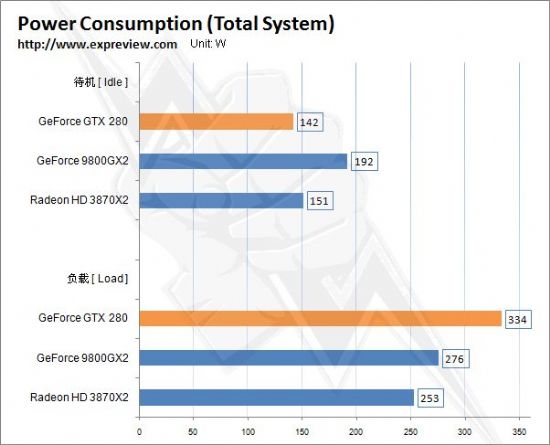
可以看到,GTX 280的功耗可以用冰火两重天来形容了,在待机时功耗比55nm制程且有“Powerplay”技术的Radeon HD 3870X2更低,仅有142W,足足低了9W,对比于同门的9800GX2(其最高整卡功耗197W),在待机下GTX 280的功耗优势非常明显,这完全取决于GTX200系列GPU中植入了先进的动态电力管理机制,比起对手的“Powerplay”似乎更胜一筹。
不过在全3D模式下,GTX 280的功耗剧增,非常之惊人,比起9800GX2和3870X2,分别高出58W和81W,功耗之王的盛名看来是非GeForce GTX 280莫属。
GeForce GTX 280温度与超频测试
◆
刚看到在高负荷下GTX 280的功耗确实惊人,GPU的温度是不是也同样惊人呢?
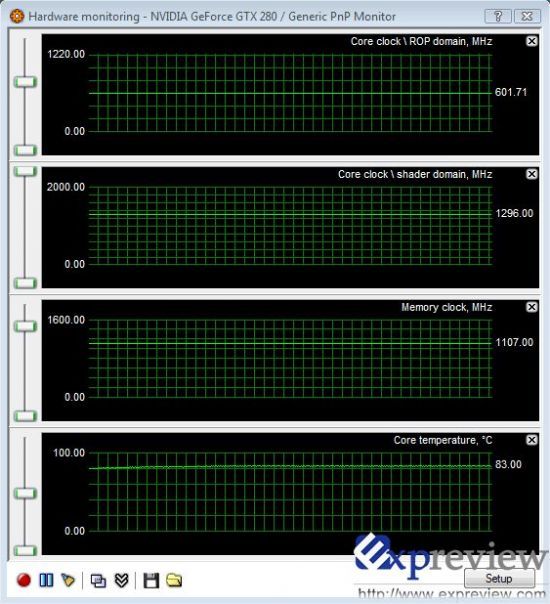
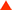 GTX 280标准频率下的GPU温度(运行ATITOOL Show 3D View) GTX 280标准频率下的GPU温度(运行ATITOOL Show 3D View) |
在默认频率下,运行ATITOOL Show 3D View时GPU的温度比我们想象中要低,不过也有83℃,在以前测试中,8800 GTS 512MB在高负载时GPU温度能达到81℃,因此对于GTX 280的发热量不用过分担心,目前的散热器还是可以压制得住的。
在比较空闲时,显卡出风口的温度约50℃,当显卡处于高速运行状态时,出风口的温度也飙升到了60多度,在夏天你会觉得阵阵热风袭来,冬天就好了,它会是很好的暖手工具。
在工作中风扇的噪音并不明显,可以观察到其转速并不快,在高负荷时转速会略有提高,噪音也是在可以接受的范围内。
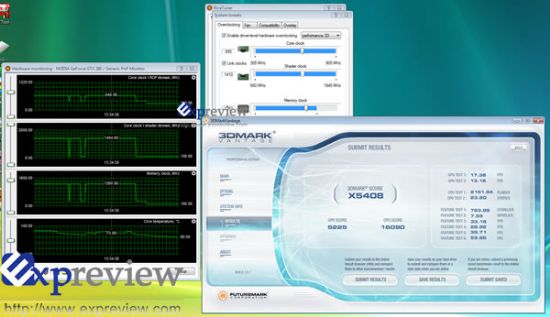
| 超频后的稳定频率为655/1410/1253MHz(点击放大) |
可能是由于个体原因,测试用的这张显卡核心频率只能由602MHz超到655MHz,相应的shader频率提升到1410MHz,显存最高可以超到1253MHz(默认频率为1107MHz,显存的规格为1200MHz),可以说核心超频能力并不高。我们另外收到的Zotac GeForce GTX 280 AMP显卡,其默认核心频率虽然达到了700MHz,但Shader频率只有1400MHz,要知道光超核心频率并没有多大作用。
原装散热器勉强可以控制住GTX 280燃烧的芯,但想要更好的超频和控制更低的温度,更换第三方散热器是必须的,目前来说,适用的散热器还几乎未见,要等上些时,不过已有厂商推出了水冷版的GTX 280。

| 七彩虹的水冷版GTX 280,只比公版贵300元 |
测试平台及说明
◆

进行测试的驱动都是目前最新的驱动程序,GeForce GTX 280使用的是Forceware 177.34 Beta驱动,从这个版本开始加入对CUDA的支持,而GeForce 9800GX2使用的是175.16 WHQL驱动,Radeon HD 3870X2则使用了最新的催化剂8.5版本。
具体的游戏设置,开启了所有可以打开的特效,并设置为最好的效果,另外AA和AF均由游戏内建的情况决定,我们不使用驱动面板进行强制性驱动,对于没有内建benchmark的游戏,采用Fraps来测试。
由于这次测试的显卡都是最顶级的,因此只测试了1680*1050和1920*1200两个分辨率下的成绩。
巅峰之战:GTX 280 vs 9800GX2
◆
在GeForce GTX 280还未面世之前,GeForce 9800GX2是这个星球上最强的娱乐级显卡,不过它是一块“SLI”模式的双GPU显卡,两者的价格也相当接近,9800GX2的参考价为$599(国内售价4999元),GTX 280的参考价为$649(国内参考售价4999元),面对规格高出很多的单GPU显卡GTX 280,双GPU的9800GX2还能保住性能王位吗?

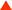 GTX 280与9800GX2测试数据对比 GTX 280与9800GX2测试数据对比 |
作为三个月前发布的产品,9800GX2虽然延用了G80的第一代统一架构,但凭借双GPU在2/5的测试项目中还是领先于GeForce GTX 280,当然更多的测试中,新一代架构的GTX 280还是取得优势,有所有34项数据中,双方互有长短,最终的结果是相对于9800GX2,GTX 280平均领先4%。
本是同根生,但GTX 280还是非常无情地将9800GX2赶下神坛,将性能王者的皇冠占为已有。
全面压倒:GTX 280 vs Radeon HD 3870X2
◆
作为对手AMD目前最高端的产品Radeon HD 3870X2,GTX 280显然也是有必要与之比较一下的,虽然我们都能料到是什么样的结果。
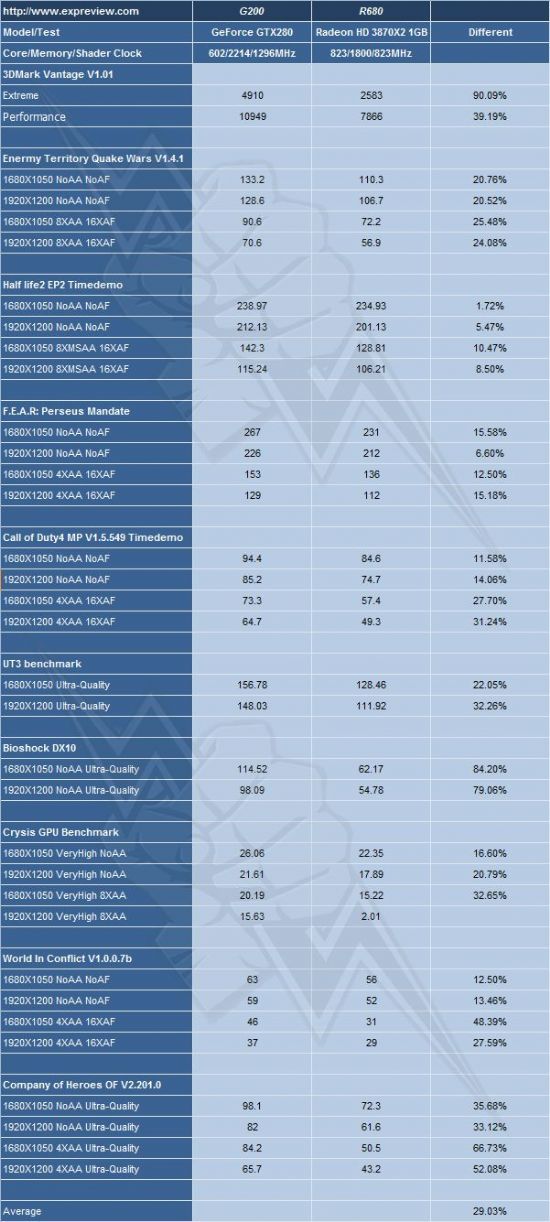
这样的结果是意料中的事,GTX 280全面压倒Radeon HD 3870X2,在以前的GeForce 9800GX2的测试中,也有很相似的结果,不过是9800GX2换成了GTX 280,双GPU换成了单GPU,可以看出NVIDIA在产品线上的一个大踏步前进。
初探GTX 260 SLI性能
◆
GTX 200系列显卡可以支持2 Way/3 Way SLI,而参考价$399的GTX 260更适合组建SLI平台,其SLI效率会如何呢?
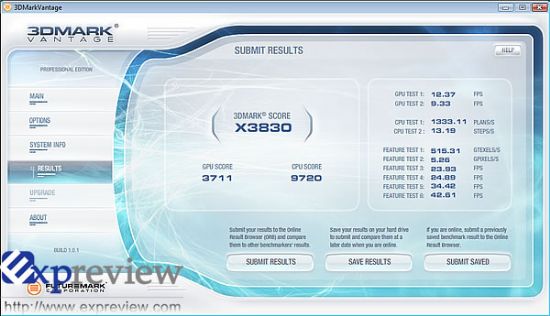
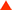 GTX 260单卡的3DMark Vantage Extreme成绩 GTX 260单卡的3DMark Vantage Extreme成绩 |
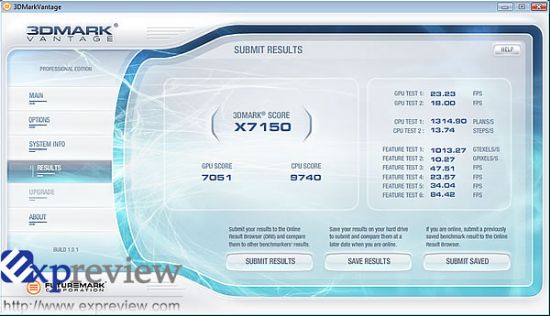
| GTX 260双卡(SLI)的3DMark Vantage Extreme成绩 |
由于时间关系,我们只能做一个简单的测试,在3DMark Vantage Extreme模式下,GTX 260 SLI的效能提升达到了86.7%,非常可观,关于这一点,我们将会继续跟进做测试测试。
体验CUDA:Folding@home
◆
Folding@home是美国史丹佛大学推动的分散式运算计划,目的在于使用联网式的计算方式和大量的分布式计算能力来模拟蛋白质折叠的过程,并指引对由折叠引起的疾病的一系列研究。ATI早在2006年就加入了这个计划,最新的客户端能支持Radeon HD 2000/3000系列显卡,NVIDIA一直无缘这项可以说是全球最普及的显卡通用计算应用。在上个月,NVIDIA宣布CUDA显卡即将加入Folding@home计划,NVIDIA表示,目前全球有7000万块CUDA显卡(GeForce 8及以上及Quadro和Tesla系列),平均拥有100GFLOPS的浮点运算能力,如果这其中有0.1%参与Folding@Home,就能够为该计划带来7PFLOPS的运算能力,远远高于全世界最强大的超级计算机(运算能力不足1PFLOPS)。
一直强调GPU Computing的GTX200系列首当其冲,我们拿到了利用CUDA开发的支持GTX200的Folding@home的客户端,进行了简单试用,在Forceware 177.34 beta驱动中开始加入了对CUDA的支持。
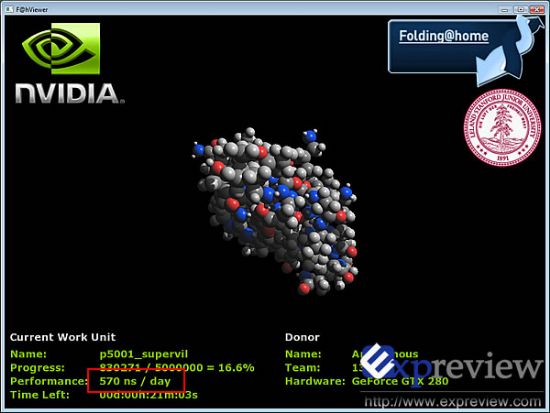
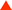 利用GTX 280的并行计算能力模拟蛋白质折叠 利用GTX 280的并行计算能力模拟蛋白质折叠 |
Folding@Home是以ns/day来衡量性能的,我们看到GTX 280能提供570ns/day的计算能力,要注意的这只是截图时的数据,实际上最后计算得到的结果是620ns/day。
作为对比,运行Folding@Home时,一颗四核心的CPU的计算能力为4ns/day,而Radeon HD3870的计算能力为170ns/day,可以看到拥用240个流处理器的GTX 280在这样的密集式并行计算中有着具大优势。
体验CUDA:Elemental transcoder
◆
利用CUDA实现GPU计算来为应用程序提速,Badaboom就是很好的一例,这是一款CUDA开发的视频转换软件,可以把mpeg2的视频转换为ipod或者iphone这样的所使用的H.264视频格式。
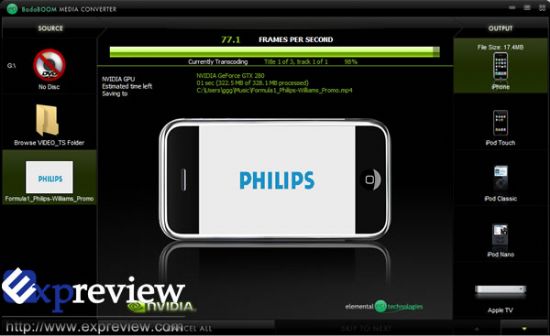
 GPU也可以给视频转换提速,处理速度达到80FPS左右,耗时37秒 GPU也可以给视频转换提速,处理速度达到80FPS左右,耗时37秒 |
我们选取了一段码率较高的MPEG2视频,可以看到GTX 280的处理速度达到了80FPS左右,如果码率较小,还可以达到100FPS以上甚至更高。328MB的MPEG2视频转换成17.4MB的iPhone可用的MP4视频(640*365),只用了37s。
同样的平台下(Intel Core2 Quad QX9650),使用Wondershare iPhone Video Converter软件进行同样的转换格式工作,相当是用CPU进行计算,得到的结果是耗时107s,几乎是用GTX 280转换耗时的三倍。
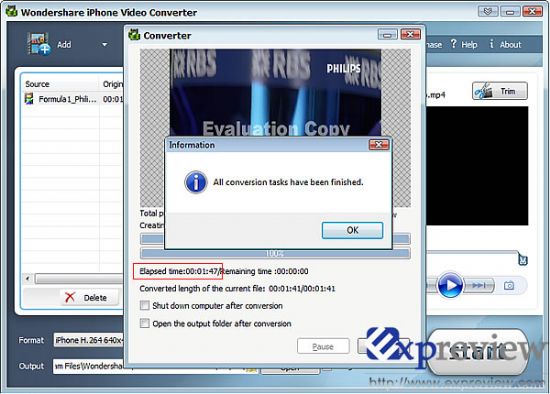
| 转换同样的视频,用CPU进行处理用时107秒 |
再一次可以领略到GPU Computing的强悍之处,相比于CPU,GPU在某些领域的计算能力确实可以达到CPU的数倍。
GTX 200的精彩:双架构设计
◆
作为图形芯片领域的领头羊,NVIDIA倡导未来GPU才是计算机核心的理念,并提出了“GPGPU(通用图形处理器)”概念,同时推出OptimizedPC的战略,鼓励电脑厂商在电脑上采用更主流的显示芯片,而减少对高性能处理器的使用,实际上也是最近“CPU和GPU到底谁重要”的话题。
GeForce GTX 200的发布并没有象以前的产品那样,大肆宣传其3D性能,而将重点放在其GPU Computing上。GeForce GTX 200同时注重并行计算和图形处理,可以说是双架构设计的统一体,在图形处理功能的基础上大幅提升了并行计算能力。GTX 200设计遵循的两个原则"Beyond Gaming"和"Gaming Beyond"实际上是双架构设计的一种很好地诠释。

 GTX 200设计遵循的两个原则:"Beyond Gaming"和"Gaming Beyond" GTX 200设计遵循的两个原则:"Beyond Gaming"和"Gaming Beyond" |
·强大的并行计算能力
GTX 280有240个处理器,其浮点运算能力达到了933GFLOPs,几乎是Intel四核处理器9650的十倍之多,意味着GPU在浮点运算中有得天独厚的优势,再加上支持双精度浮点运算以及142GB/s的显存带宽等增强特性,使得GTX 280拥有强大的并行计算能力,而基于C语言的CUDA平台被越来越多的开发者所采用,CUDA 2.0的发布也让它变得更加易于使用,GTX 200对于NVIDIA的“GPGPU”理念将会有着非常重要的推动作用,意义非凡。
在我们测试的两个CUDA应用实例中,可以发现GTX 280在分布式计算和密集型计算时有着比CPU强上很多倍的能力,随着CUDA的飞速发展,越来越多的程序可以使用GPU来作计算,处理能力比CPU更为强悍,无论对于消费者还是NVIDIA来说,都是非常乐观和期待的。
另外随着驱动对PhysX的支持,玩家更是可以体验到物理加速的快感。
·无与伦比的图形处理能力
和GTX 200的并行计算能力相比,这次它在3D性能方面显得要低调很多,而实际上,GTX 280却拥有无与伦比的图形处理能力,240个SP、512bit显存带宽、1GB的显存,这些历史最高记录已经让它出落成一个人见人爱的“大美人”,各路诸雄无不拜倒在它裙下,相比双GPU的GeForce 9800GX2和Radeon HD 3870X2,各有4%和29%的领先,这足以让GTX 280成为这个宇宙最强的娱乐级显卡。
GTX 200的SLI效率也很不错,初步测试的结果显示能达到80%以上,另一方面,它的动态电耗管理也是一个亮点,在待机下能显著减少能耗,有很好的实际价值。
·GTX 280参考售价4999元

| GTX 200将会取代现在9800GX2的位置 |
GeForce GTX 280的官方参考价为649美元,国内参考价基本在4999元,将在会17号大量铺货,而参考价399美元的GTX 260的铺货时间则要等到6月26号。
我们在以前就报道过,GeForce 9800GX2的寿命只有三四个月,现在看不假,GTX 200将会取代现在9800GX2的位置,9800GX2或许是历史上最短命的性能之王吧?
不管怎么说,GTX 200有着许多值得一写的地方,对于NVIDIA来说,GTX 200是一颗很重要的旗子,除了要占领3D性能的制高点外,更是要去抢CPU的饭碗,GPU与CPU之争的好戏还在后头呢。












 康佳平板电视
康佳平板电视 创维平板电视
创维平板电视
 LG平板电视
LG平板电视 长虹平板电视
长虹平板电视 WAP手机版
WAP手机版 建议反馈
建议反馈 官方微博
官方微博 微信扫一扫
微信扫一扫